 von Feldern in Rio Grande do Sul, Brasilien vom 12. 4. 2020 (Planet)")
Maximum-Likelihood-Klassifizierung
Engl. maximum likelihood classifier / classification, franz. méthode du maximum de vraisemblance; in der Fernerkundung eine überwachte Klassifizierung nach der Methode der größten Wahrscheinlichkeit. Dabei müssen in einem ersten Schritt Trainingsgebiete für jede zu klassifizierende Klasse erhoben werden. Es ist zu beachten, dass diese Gebiete homogen sind und keine anderen Klassen vorkommen, weil dadurch die Statistiken verfälscht würden. Für jedes dieser Gebiete werden im Folgenden statistische Werte (Mittelwert und Standardabweichung) ermittelt. Diese werden in der nachfolgenden Klassifizierung als Maß für die Zuweisung eines Pixels zu einer bestimmten Klasse verwendet (vgl. Abb.).
Eine statistische Entscheidungsregel prüft die Wahrscheinlichkeitsdichte, mit der ein Pixel zu den Klassen mit der vorgegebenen A-priori-Wahrscheinlichkeit gehört und weist es der Klasse mit dem höchsten Wert zu. Im Gegensatz zur Minimaldistanz-Klassifikation wird hier nicht mit mehrdimensional isotroper Distanz operiert, sondern es geht auch die multivariate Streuungsinformation als Richtungsdifferenzierung im Merkmalsraum mit ein.
Während der Rechenaufwand dieser Technik hoch ist, sind dafür die Klassifikationsergebnisse in der Regel denen alternativer Ansätze überlegen. Zusätzlich besteht auch noch die Möglichkeit statistischer Qualitätsaussagen hinsichtlich der Klassifikation jedes einzelnen Pixels aufgrund der bekannten Verteilungseigenschaften, die aus der mehrdimensionalen Stichprobe der Trainingsgebiete geschätzt werden.
Somit können bewusst Qualitätsentscheidungen getroffen werden, wie etwa Pixel mit weniger als 95 % Sicherheit als "nicht klassifiziert" zu identifizieren. Ebenso können auch a-priori Wahrscheinlichkeiten etwa auf Grund des vorab bekannten Anteiles einzelner Klassen innerhalb des Untersuchungsgebietes festgelegt werden.
Die Maximum-Likelihood-Methode ist die genaueste Klassifizierung, da sie die meisten Variablen berücksichtigt.
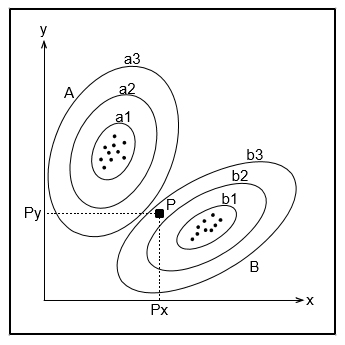 | Maximum-Likelihood-Klassifikation Zuweisung der Pixels P zur Klasse B, aufgrund der höheren Wahrscheinlichkeit Für zwei Klassen A und B sind in der Abb. die Werte aller in den Trainingsgebieten vorkommenden Pixelwerte aufgetragen (x-Achse entspricht Band 1 und y-Achse entspricht Band 2). Diese Klassen bilden eine Clusterwolke. Die um diese Wolken gezeichneten Ellipsen stellen die berechneten statistischen Werte dar. Den Mittelpunkt der Ellipse bildet der Mittelwert und die Größe der Ellipse hängt von der Standardabweichung der Clusterwolke ab. Aufgezeichnet sind die Ellipsen für die ein- (a1, b1), zwei- (a2, b2) und dreifache (a3, b3) Standardabweichung. Ein zu klassifizierender Punkt P mit dem Wert Px in Band 1 und Wert Py in Band 2 wird nun der Klasse zugewiesen, zu der der Abstand in Abhängigkeit von der Standardabweichung am geringsten ist. Der Punkt liegt innerhalb der dreifachen Standardabweichung der Klasse B und außerhalb der dreifachen Standardabweichung der Klasse A, somit wird dieser Pixel der Klasse B zugewiesen. Quelle: LFULG |
Weitere Informationen:
- Maximum Likelihood Classification (iGETT / YouTube)