 von Feldern in Rio Grande do Sul, Brasilien vom 12. 4. 2020 (Planet)")
unüberwachte Klassifizierung
Syn. automatische Klassifizierung, ISODATA-Klusterung; engl. unsupervised classification, franz. classification non dirigée, classification non supervisée; statistisches Verfahren, das bei digitaler Bildbearbeitung Klassenbildungen ohne Referenzdaten, d.h. ohne Vorgaben aus Trainingsgebieten ermöglicht. Ziel dieser Verfahren ist, Bildelemente, die im Merkmalsraum durch Merkmalsvektoren dargestellt werden, so in Cluster zusammenzufassen, dass jede dieser Ballungen einer homogenen Bildregion entspricht. Die Cluster werden aufgrund der Ähnlichkeit der Pixel gebildet, wobei Ähnlichkeit durch Nachbarschaft im Merkmalsraum operationalisiert wird. Hierbei werden vorab keine Informationen über die zu ermittelnden Cluster benötigt. Der Bearbeiter bestimmt lediglich die Clusterzahl.
Sämtliche Bildelemente werden also lediglich aufgrund statistischer Parameter verschiedenen Klassen zugeordnet. Der Bearbeiter hat die Aufgabe, die aufgefundenen Klassen nachträglich thematisch zu definieren, wobei üblicherweise verschiedene Referenzinformationen (Geländeerhebungen, Spektralmessungen, Karten usw.) genutzt werden.
Dem Rechner wird unter Vorgabe bestimmter Parameter überlassen, die Zuordnung der Rasterpixel zu verschiedenen Spektralklassen durchzuführen. Im ersten Schritt wird mit einer Clusterbildung (Wertegruppierung basierend auf ähnlichen statistischen Eigenschaften) in einer Satellitenbildszene untersucht, wieviele ähnliche Rasterzellenwerte (sie entsprechen den Farben im Bild) vorliegen und zu einem Wert zusammengefasst werden können. Vergleichbar ist das mit der Erstellung einer Legende bei einer Karte, bei der zunächst untersucht wird, wie viele Kartensignaturen es überhaupt gibt. Die Zuordnung zu den räumlichen Einheiten erfolgt später im zweiten Schritt. Der iterativ Clusteralgorithmus berechnet zunächst also Clustermittelwerte und Kovarianzmatrizen. Dafür wird eine Auswertung der Häufigkeitsverteilung der einzelnen Rasterwerte in den einzelnen Kanälen (zwei- bis mehrdimensional) durchgeführt.
Als Ergebnis bilden sich abgegrenzte "Punktwolken", also die Abgrenzung von Häufigkeitskonzentrationen (vgl. Abb.). Jede "Wolke" charakterisiert eine bestimmte Objektreflexion und wird als eine Klasse (Cluster) zusammengefasst. Sie steht in direktem Zusammenhang mit den kanal- und pixelweise ermittelten Objektreflexionen. Aus diesem Grunde werden auch mindestens zwei Bilddatensätze benötigt, um eine Clusterung durchzuführen. Mit diesen gewonnenen statistischen Werten erfolgt dann die räumliche Zuordnung der einzelnen Pixel nach der größten Wahrscheinlichkeit ihrer Klassenzugehörigkeit (Maximum Likelihood Diskriminant-Analyse).
Die Verfahren unterscheiden sich u.a. in den Eingangsparametern, teilweise werden Angaben wie z.B. Klassenanzahl oder Festlegung der Keimpunkte, d.h. jener Punkte, die als Ursprung einer Klasse dienen, benötigt.
Im Gegensatz zur überwachten Klassifizierung liegen Informationen zu thematischen Inhalten bzw. Zugehörigkeiten zu tatsächlichen Objektklassen zunächst nicht vor. Sie werden in der Nachbearbeitung zugewiesen, sofern dies überhaupt möglich ist.
Clusterverfahren haben einen besonderen Nutzen, wenn man nur wenig Wissen über das Gebiet hat oder keine falschen Wissensaspekte in den Klassifikationsprozess mit einfließen lassen möchte. Sie können auch als Vorprozessierungsschritt zur überwachten Klassifikation genutzt werden.
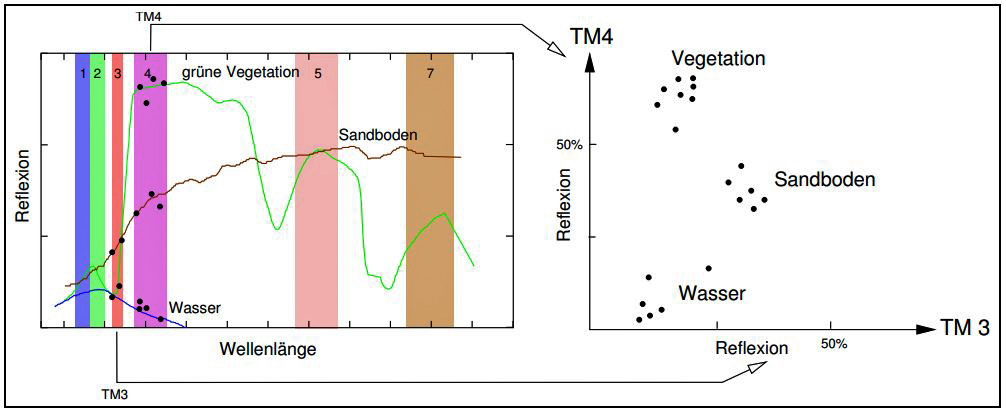 Häufigkeitsverteilung der Pixelwerte zweier Satellitenbildkanäle | Unüberwachte Klassifizierung Die unüberwachte Klassifizierung ist die Zuordnung der Rasterpixel zu verschiedenen Spektralklassen auf automatisiertem Wege. Dabei wird dem Rechner unter Vorgabe bestimmter Parameter überlassen, diese Zuordnung durchzuführen. Als Ergebnis bilden sich abgegrenzte "Punktwolken" (vgl. Abb.). Jede "Wolke" charakterisiert eine bestimmte Objektreflexion und wird als eine Klasse (cluster) zusammengefasst. Mit diesen gewonnenen statistischen Werten erfolgt dann die räumliche Zuordnung der einzelnen Pixel nach der größten Wahrscheinlichkeit ihrer Klassenzugehörigkeit (Maximum Likelihood Diskriminant-Analyse). Quelle: Grass-Handbuch (M. Neteler) |