 von Feldern in Rio Grande do Sul, Brasilien vom 12. 4. 2020 (Planet)")
Big Data
Der weit gefasste Begriff "Big Data" beinhaltet Methoden und Werkzeuge für das Zusammenführen sehr großer Datenmengen aus heterogenen, sich häufig verändernden Datenquellen. Dabei bezieht sich "Big" gleichermaßen auf das große Datenvolumen, die hohe Übertragungsgeschwindigkeit und die Bandbreite der Datenquellen. Diese Daten stellen besondere Anforderungen an die Datenverarbeitung und die Datenanalyse.
In der Informatik werden Big Data durch „5 Vs“ charakterisiert:
- Volume (Datenmenge),
- Variety (Vielfalt & Komplexität der Daten),
- Velocity (Geschwindigkeit der Erzeugung),
- Veracity (Zuverlässigkeit / Herkunft / Tauglichkeit für jeweiligen Zweck) und
- Value (Wert).
Die 5 Vs lassen sich z. B. auch in geowissenschaftlichen Daten wiederfinden.
Der rasante technologische Fortschritt in der Sensorentwicklung und der Computersimulation ermöglicht es Wissenschaftlerinnen und Wissenschaftlern, immer größere Datenmengen mit einer Vielzahl unterschiedlicher Parameter zu generieren. Ein Beispiel für große Datenmengen am Deutschen GeoForschungsZentrum (GFZ) sind optische Satellitendaten. Diese Daten werden genutzt, um Zustand und Veränderung der Erdoberfläche, wie z. B. Landnutzung, schnell zu erfassen. Die Datenmengen dieser Anwendungen liegen im Petabyte-Bereich (PB), wobei 1 PB = 1000 Terabyte (TB) entsprechen. Für die Speicherung dieser Datenmengen werden schon heute in der Regel mehrere Hundert handelsübliche Festplatten benötigt (s. Tab.). Die Datenmengen werden in Zukunft mit der Verfügbarkeit neuer Satellitensysteme enorm anwachsen. Die Geschwindigkeit, mit der geowissenschaftliche Daten generiert werden, steigt zudem stetig mit dem anhaltenden Fortschritt in der Sensor- und Rechentechnik.
| Optische Satellitendaten verschiedener Missionen als Beispiel für große Datenmengen am GFZ 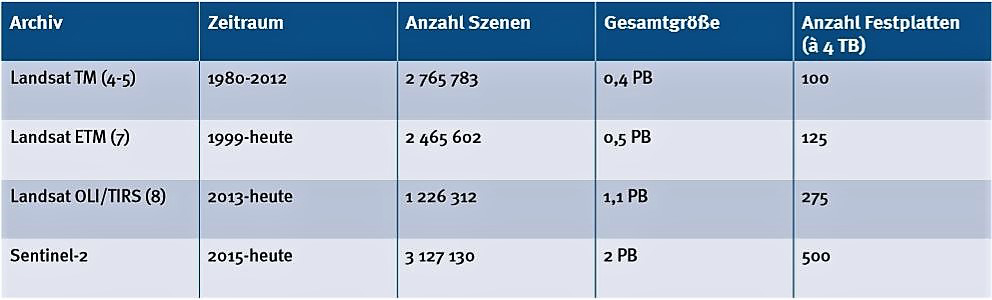 Quelle: GFZ Quelle: GFZ |
Die durch die vielfältigen Sensorsysteme und Simulationsmodelle erzeugten Daten müssen zueinander in Beziehung gesetzt werden, um das komplexe System Erde mit seinen ablaufenden Prozessen verstehen zu können. Die gemeinsame Verarbeitung und Analyse der Daten ist eine anspruchsvolle Aufgabe, da die Daten sehr heterogen sind. Sie beschreiben die Prozesse des Erdsystems durch unterschiedliche Variablen, in verschiedenen räumlichen und zeitlichen Auflösungen, in unterschiedlicher räumlicher und zeitlicher Verteilung und mit unterschiedlicher Zuverlässigkeit. Die erfassten Daten sind Basis der wissenschaftlichen Arbeit und daher von großem Wert, was sich in den vielen Bestrebungen zu einem effektiven Management von Forschungsdaten mit entsprechenden Infrastrukturen widerspiegelt.
Die Herausforderungen an die Datenverarbeitung und die Datenanalyse, die sich aus den 5 Vs ergeben, werden in Zukunft dringende Forschungsaspekte in den Geowissenschaften sein. Ein Beispiel dafür ist die schnelle Extraktion relevanter Informationen und Muster aus großen Datenmengen. Erforderlich dafür sind zum einen die Entwicklung effizienter und skalierbarer geowissenschaftlicher Analysemethoden und zum anderen die Anpassung geowissenschaftlicher Methoden an Big-Data-Technologien. (Sips 2018)
Insbesondere mit den Daten der Sentinel-Satelliten und in Zukunft auch der Satelliten Tandem-L und EnMap ist die Fernerkundung unumkehrbar in der Big Data Ära angekommen. Dies erfordert nicht nur neue technologische Ansätze, um die großen Datenmengen zu verwalten, sondern auch neue Analysemethoden. Beides wird z. B. am DLR erforscht
In diesem Zusammenhang werden Methoden aus der Data Science und der künstlichen Intelligenz, wie maschinelles Lernen, unverzichtbar. Insbesondere Deep Learning hat in dem Bereich der künstlichen Intelligenz in den letzten Jahren das Feld revolutioniert. Eine besondere Herausforderung besteht in der Integration heterogener Erdbeobachtungsdaten, ihre parallele Analyse sowie die Visualisierung der Ursprungsdaten und Analyseergebnisse zur korrekten Detektion und Bewertung raum-zeitlicher Veränderungen der Erdoberfläche.
Weitere Informationen:
- GeoMultiSens - Skalierbare multisensorale Analyse von Geofernerkundungsdaten (Sips et al. 2018, GFZ)